
12 Aprile 2022 di Daniele Frulla
A volte è molto più veloce scrivere una riga di codice che trovare un bel programma grafico che ci risolva il problema.
Come modificare files l’ho scoperto quando ero impegnato a gestire file PDF per separarli, unirli, convertirli in html o testo.
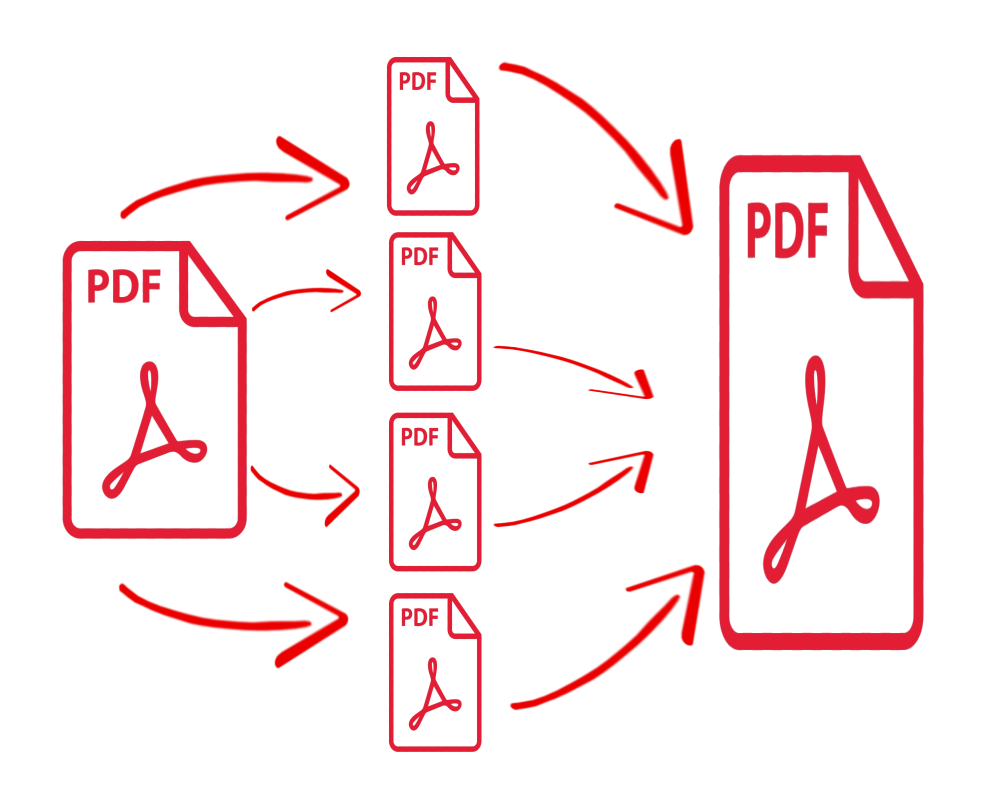
Il software di cui parlo è il pacchetto open source plopper-utils scaricabile col semplice comando:
apt install poppler-utilsSi trova di default su macchine Ubuntu, ma possiamo utilizzarlo su macchine linux derivazione Debian.
Se vediamo cosa contiene il pacchetto vedremo:
# apt show poppler-utils
Package: poppler-utils
Version: 0.86.1-0ubuntu1
Priority: optional
Section: utils
Source: poppler
Origin: Ubuntu
Maintainer: Ubuntu Developers <[email protected]>
Original-Maintainer: Debian freedesktop.org maintainers <[email protected]>
Bugs: https://bugs.launchpad.net/ubuntu/+filebug
Installed-Size: 754 kB
Provides: pdftohtml, xpdf-utils
Depends: libpoppler97 (= 0.86.1-0ubuntu1), libc6 (>= 2.14), libcairo2 (>= 1.12.0), libfreetype6 (>= 2.2.1), liblcms2-2 (>= 2.2+git20110628), libstdc++6 (>= 5.2)
Conflicts: pdftohtml
Breaks: xpdf-common, xpdf-utils (<< 1:0)
Replaces: pdftohtml, xpdf-reader, xpdf-utils (<< 3.02-2~)
Homepage: http://poppler.freedesktop.org/
Task: print-server, ubuntu-desktop-minimal, ubuntu-desktop, kubuntu-desktop, xubuntu-core, xubuntu-desktop, lubuntu-desktop, ubuntustudio-desktop-core, ubuntustudio-desktop, ubuntukylin-desktop, ubuntu-mate-core, ubuntu-mate-desktop, ubuntu-budgie-desktop
Download-Size: 174 kB
APT-Manual-Installed: no
APT-Sources: http://it.archive.ubuntu.com/ubuntu focal/main amd64 Packages
Description: PDF utilities (based on Poppler)
Poppler è una libreria di rendering per PDF basata sul visualizzatore di
PDF xpdf.
.
This package contains command line utilities (based on Poppler) for getting information of PDF documents, convert them to other formats, or manipulate them:
* pdfdetach -- lists or extracts embedded files (attachments)
* pdffonts -- font analyzer
* pdfimages -- image extractor
* pdfinfo -- document information
* pdfseparate -- page extraction tool
* pdfsig -- verifies digital signatures
* pdftocairo -- PDF to PNG/JPEG/PDF/PS/EPS/SVG converter using Cairo
* pdftohtml -- PDF to HTML converter
* pdftoppm -- PDF to PPM/PNG/JPEG image converter
* pdftops -- PDF to PostScript (PS) converter
* pdftotext -- text extraction
* pdfunite -- document merging toolAbbiamo dei bei software per la gestione del nostro PDF.
Per l’unione di file pdf:
pdfunite pdf1.pdf pdf2.pdf pdf3.pdf PDFTotale.pdfEd ecco fatto, abbiamo il nostro file PDFTotale.pdf risultato dell’unione degli altri tre files.
La separazione di pagine pdf è altrettanto semplice:
pdfseparate -f 30 -l 33 PDFTotale.pdf Pagine%d.pdfCon il comando sopra estraiamo le pagine dalla 30 alla 33 dal file PDFTotale.pdf e le chiamiamo Pagine30.pdf, Pagine31.pdf, Pagine32.pdf, Pagine33.pdf.
Se ha un PDF e vuoi convertirlo direttamente in HTML allora scrivi:
pdftohtml File.pdf sito/indexNella cartella sito, troverai le pagine html richiamabile da index.html.
Per ora mi fermo qui.
Puoi provare anche tu a eseguire questi tools, magari consultandone il manuale.
Se poi vuoi convertire il tuo pdf in immagini puoi consultare il post fatto precedentemente come appunto.







Lascia un commento